xddlovejiao1314 发表于 2015-7-1 11:00 
最后一个问题,我看到的这么多的关于Logistic模型的书或者文献,还没有见过用自变量标准差变化去解释因变量 ...
十分感谢版主的热情解答,有拨云见日之感,还有几个问题向版主进一步请教:
1.logistic回归时,连续自变量等级化之后,P for trend如何在SPSS中计算?
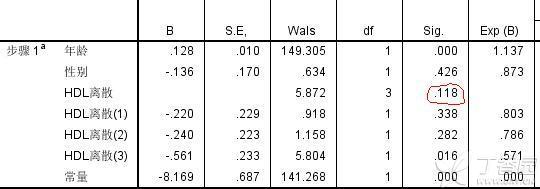
2.我在分析时确实将分类自变量设置了哑变量(将HDL选入分类协变量框,并以HDL第一水平为参照),但仍会出现红圈中的P值,不过如果它没有特殊意义,我也不必纠结了
3.我是医学专业的,实际问题中,自变量常常会有很多连续变量,如年龄和各种血液指标等,如果把每个自变量都变成等级变量,将会大大增加自变量的个数,所以实际上,许多自变量还是作为连续变量进入方程的,这种情况下,我见到许多文献都有这样的说法:“某指标浓度每改变一个标准差,因变量出现某种结果的可能性增加多少”,相对的,“某指标浓度每改变1mmol/L”,这样的说法极少出现,其原因也不能理解,因为许多指标的浓度范围就是零点几个毫摩尔每升,因此用1mmol/L显然太大了,所以用一个标准差比较合适。我想知道的是这种做法是如何实现的,我见到有人说先将自变量标准化之后,做出来的OR值就是标准化的OR值,也有人说,logistic的标准回归系数=回归系数×S.D./1.8138,请版主进一步指教。
再次感谢!


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏