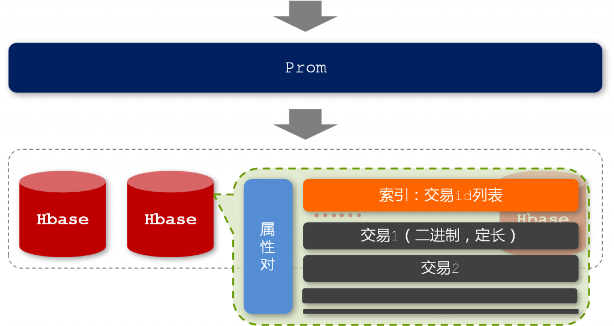
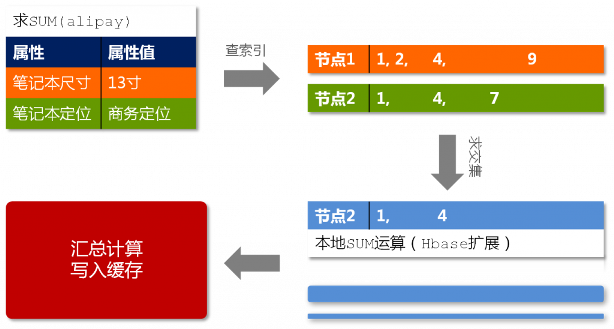
在图8中我们看到,glider中存在两层缓存,分别是基于各个异构“表”(datasource)的二级缓存和整合之后基于独立请求的一级缓存。除此之外,各个异构“表”内部可能还存在自己的缓存机制。细心的读者一定注意到了图3中MyFOX的缓存设计,我们没有选择对汇总计算后的最终结果进行缓存,而是针对每个分片进行缓存,其目的在于提高缓存的命中率,并且降低数据的冗余度。
大量使用缓存的最大问题就是数据一致性问题。如何保证底层数据的变化在尽可能短的时间内体现给最终用户呢?这一定是一个系统化的工程,尤其对于分层较多的系统来说。
图9 缓存控制体系
图9向我们展示了数据魔方在缓存控制方面的设计思路。用户的请求中一定是带了缓存控制的“命令”的,这包括URL中的query string,和HTTP头中的“If-None-Match”信息。并且,这个缓存控制“命令”一定会经过层层传递,最终传递到底层存储的异构“表”模块。各异构“表”除了返回各自的数据之外,还会返回各自的数据缓存过期时间(ttl),而glider最终输出的过期时间是各个异构“表”过期时间的最小值。这一过期时间也一定是从底层存储层层传递,最终通过HTTP头返回给用户浏览器的。
缓存系统不得不考虑的另一个问题是缓存穿透与失效时的雪崩效应。缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。在数据魔方里,我们采用了一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存失效时的雪崩效应对底层系统的冲击非常可怕。遗憾的是,这个问题目前并没有很完美的解决方案。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。在数据魔方中,我们设计的缓存过期机制理论上能够将各个客户端的数据失效时间均匀地分布在时间轴上,一定程度上能够避免缓存同时失效带来的雪崩效应。
结束语
正是基于本文所描述的架构特点,数据魔方目前已经能够提供压缩前80TB的数据存储空间,数据中间层glider支持每天4000万的查询请求,平均响应时间在28毫秒(6月1日数据),足以满足未来一段时间内的业务增长需求。
尽管如此,整个系统中仍然存在很多不完善的地方。一个典型的例子莫过于各个分层之间使用短连接模式的HTTP协议进行通信。这样的策略直接导致在流量高峰期单机的TCP连接数非常高。所以说,一个良好的架构固然能够在很大程度上降低开发和维护的成本,但它自身一定是随着数据量和流量的变化而不断变化的。我相信,过不了几年,淘宝数据产品的技术架构一定会是另外的样子。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏