经管之家App
让优质教育人人可得
立即打开


A discussion and step-by-step tutorial on how to use Tensorflow graphs for multi-task learning.
By Jonathan Godwin, University College London.
IntroductionA Jupyter notebook accompanies this blog post. Please download here.
Why Multi-Task Learning
When you think about the way people learn to do new things, they often use their experience and knowledge of the world to speed up the learning process. When I learn a new language, especially a related one, I use my knowledge of languages I already speak to make shortcuts. The process works the other way too - learning a new language can help you understand and speak your own better.
Our brains learn to do multiple different tasks at the same time - we have the same brain architecture whether we are translating English to German or English to French. If we were to use a Machine Learning algorithm to do both of these tasks, we might call that ‘multi-task’ learning.
It’s one of the most interesting and exciting areas of research for Machine Learning in coming years, radically reducing the amount of data required to learn new concepts. One of the great promises of Deep Learning is that, with the power of the models and simple ways to share parameters between tasks, we should be able to make significant progress in multi-task learning.
As I started to experiment in this area I came across a bit of a road block - while it was easy to understand the architecture changes required to implement multi-task learning, it was harder to figure out how to implement it in Tensorflow. To do anything but standard nets in Tensorflow requires a good understanding of how it works, but most of the stock examples don’t provide helpful guidance. I hope the following tutorial explains some key concepts simply, and helps those who are struggling.
What We Are Going To Do
Part 1
Part 2
The Computation Graph is the thing that makes Tensorflow (and other similar packages) fast. It’s an integral part of machinery of Deep Learning, but can be confusing.
There are some neat features of a graph that mean it’s very easy to conduct multi-task learning, but first we’ll keep things simple and explain the key concepts.
Definition: Computation Graph
The Computation Graph is a template for computation (re: algorithm) you are going to run. It doesn’t perform any calculations, but it means that your computer can conduct backpropagation far more quickly.
If you ask Tensorflow for a result of a calculation it will only make those calculations required for the job, not the whole graph.
A Toy Example - Linear Transformation: Setting Up The Graph
We’re going to look at the graph for a simple calculation - a linear transformation of our inputs, and taking the square loss:
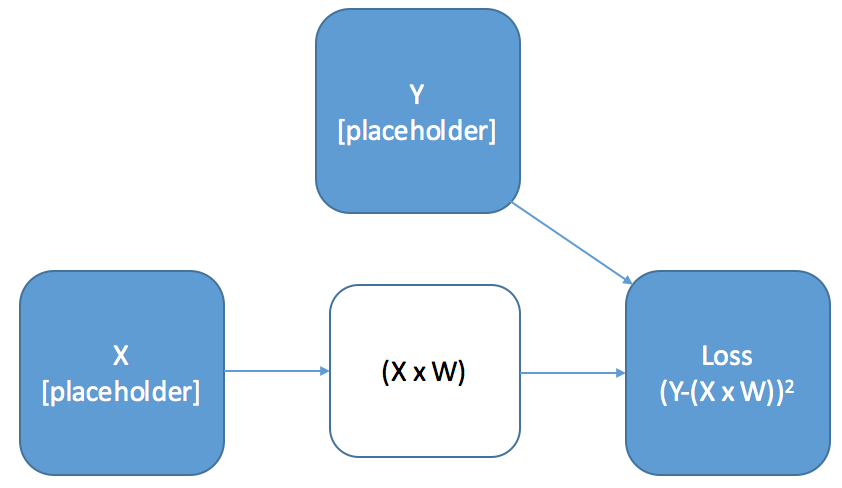
There are a few things to emphasis about this graph:
Tip: Keep Your Graph Separate. You’ll typically be doing a fair amount of data manipulation and computation outside of the graph, which means keeping track of what is and isn’t available inside of python a bit confusing. I like to put my graph in a separate file, and often in a separate class to keep concerns separated, but this isn’t required.
A Toy Example - Linear Transformation: Getting Results
Computations on your Graph are conducted inside a Tensorflow Session. To get results from your session you need to provide it with two things: Target Results and Inputs.
When we create a Neural Net that performs multiple tasks we want to have some parts of the network that are shared, and other parts of the network that are specific to each individual task. When we’re training, we want information from each task to be transferred in the shared parts of the network.
So, to start, let’s draw a diagram of a simple two-task network that has a shared layer and a specific layer for each individual task. We’re going to feed the outputs of this into our loss function with our targets. I’ve labelled where we’re going to want to create placeholders in the graph.

When we are training this network, we want the parameters of the Task 1 layer to not change no matter how wrong we get Task 2, but the parameters of the shared layer to change with both tasks. This might seem a little difficult - normally you only have one optimiser in a graph, because you only optimise one loss function. Thankfully, using the properties of the graph it’s very easy to train this sort of model in two ways.

The first solution is particularly suited to situations where you’ll have a batch of Task 1 data and then a batch of Task 2 data.
Remember that Tensorflow automatically figures out which calculations are needed for the operation you requested, and only conducts those calculations. This means that if we define an optimiser on only one of the tasks, it will only train the parameters required to compute that task - and will leave the rest alone. Since Task 1 relies only on the Task 1 and Shared Layers, the Task 2 layer will be untouched. Let’s draw another diagram with the desired optimisers at the end of each task.
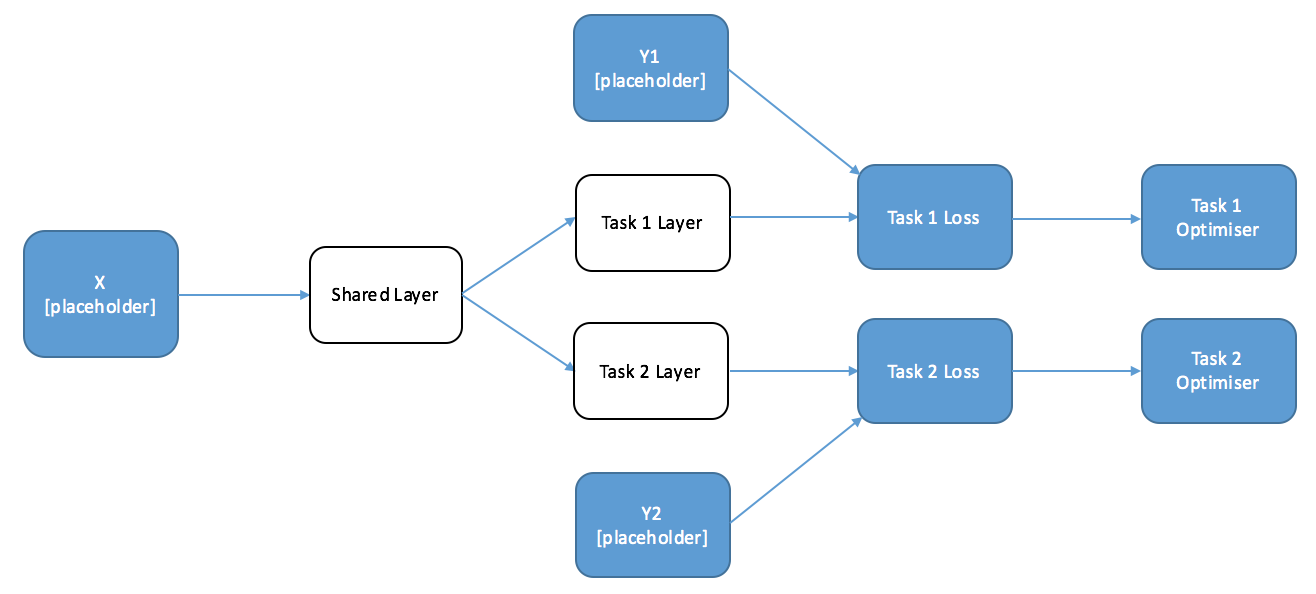
We can conduct Multi-Task learning by alternately calling each task optimiser, which means we can continually transfer some of the information from each task to the other. In a loose sense, we are discovering the ‘commonality’ between the tasks. The following code implements this for our easy example. If you are following along, paste this at the bottom of the previous code:
# Calculation (Session) Code# ==========================# open the sessionwith tf.Session() as session: session.run(tf.initialize_all_variables()) for iters in range(10): if np.random.rand() < 0.5: _, Y1_loss = session.run([Y1_op, Y1_Loss], { X: np.random.rand(10,10)*10, Y1: np.random.rand(10,20)*10, Y2: np.random.rand(10,20)*10 }) print(Y1_loss) else: _, Y2_loss = session.run([Y2_op, Y2_Loss], { X: np.random.rand(10,10)*10, Y1: np.random.rand(10,20)*10, Y2: np.random.rand(10,20)*10 }) print(Y2_loss)Tips: When is Alternate Training Good?
Alternate training is a good idea when you have two different datasets for each of the different tasks (for example, translating from English to French and English to German). By designing a network in this way, you can improve the performance of each of your individual tasks without having to find more task-specific training data.
Alternate training is the most common situation you’ll find yourself in, because there aren’t that many datasets that have two or more outputs. We’ll come on to one example, but the clearest examples are where you want to build hierarchy into your tasks. For example, in vision, you might want one of your tasks to predict the rotation of an object, the other what the object would look like if you changed the camera angle. These two tasks are obviously related - in fact the rotation probably comes before the image generation.
Tips: When is Alternate Training Less Good?
Alternate training can easily become biased towards a specific task. The first way is obvious - if one of your tasks has a far larger dataset than the other, then if you train in proportion to the dataset sizes your shared layer will contain more information about the more significant task.
The second is less so. If you train alternately, the final task in your model will create a bias in the parameters. There isn’t any obvious way that you can overcome this problem, but it does mean that in circumstances where you don’t have to train alternately, you shouldn’t.
Training at the Same Time - Joint Training
When you have a dataset with multiple labels for each input, what you really want is to train the tasks at the same time. The question is, how do you preserve the independence of the task-specific functions? The answer is surprisingly simple - you just add up the loss functions of the individual tasks and optimise on that. Below is a diagram that shows a network that can train jointly, with the accompanying code:

In this post we’ve gone through the basic principles behind multi-task learning in deep neural nets. If you’ve used Tensorflow before, and have your own project, then hopefully this has given you enough to get started.
For those of you who want a more meaty, more detailed example of how this can be used to improve performance in multiple tasks, then stay tuned for part 2 of the tutorial where we’ll delve into Natural Language Processing to build a multi-task model for shallow parsing and part of speech tagging.
Bio: Jonathan Godwin is currently studying for a Msc in Machine Learning from UCL with a specialism in deep multi-task learning for NLP. He will be finishing in September and will be looking for jobs/research roles where he can use this skill set on interesting problems.
 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏




