《聪明的Alpha,万剑归宗!》主要是在以前构建的Smart Alpha动态选股模型之上对机器学习算法用于选股的再探索。本篇我们主要考察了决策树类的机器学习算法,该方法的逻辑类似于我们通常按照因子分层筛选股票的决策过程。
首先我们考察了基础的决策树模型,而后在此之上,我们分别建立了随机森林模型和提升树模型,这两个方法都是通过构建多棵决策树以综合其所有子树的预测能力来实现表现的提升。
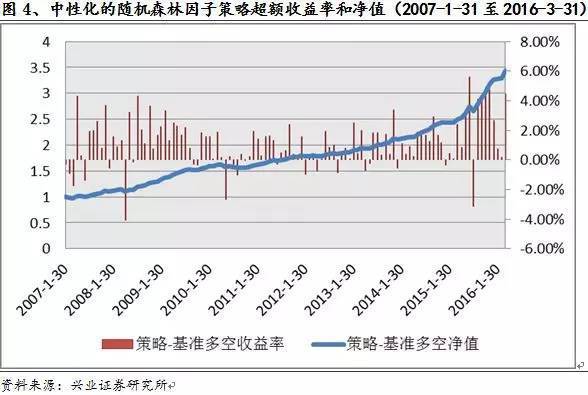
基于表现较好的中性化的随机森林因子,我们以中证500为基准构建了量化对冲选股策略,年化的超额收益率达到了 14.40%,收益风险比为 2.54,最大回撤 4%。
决策树
像树一样思考 决策树本质上是从训练数据集中归纳出了一组分类规则,其模型呈现树形结构。决策树由节点和有向边组成,节点有两类:内部节点(包括根节点)和叶节点。内部节点表示一个属性或者规则,在我们的选股模型里可以认为是一个因子,而叶节点表示一个类别。用决策树分类,从根节点开始,对某一个属性或者因子进行测试,根据结果将实例分配到其下层的一个子节点,如果该子节点是叶节点,则用该叶节点对应的类别给实例分类,如果不是叶节点,则重复上述过程,直至到达某个叶节点。
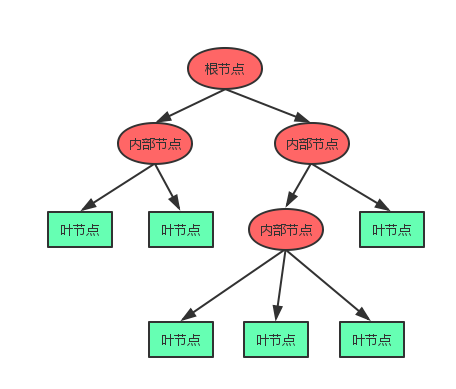
将决策树方法用于构建多因子模型进行选股的背后逻辑类似于我们通常按照因子分层筛选股票的决策过程。通常,我们首先考虑最重要的因子,用其筛选出一部分股票,这对应于决策树方法在构建节点时挑选出当前区分能力最强(信息增益最大)的属性对样本进行划分。接下来我们会再挑选次重要的因子继续精选股票,这相当于构建决策树时在上层节点的子节点上继续重复挑选划分过程。


随机森林
积沙成塔,聚木成林 随机森林是利用多棵决策树对样本进行训练并预测的一种分类器。它用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。随机性来源于在构建每个单独的决策树时,从训练样本中随机采集子样本以及在所有因子中随机采集因子子集来进行训练。在进行预测时,对于一个新的样本,森林中的每一棵决策树分别进行一下判断,最后综合所有决策树的判断给出最终结果。森林中的每一棵决策树的预测能力可能不是很强,但所谓众人拾柴火焰高,整个森林的预测能力会得到提升。
提升树 三个臭皮匠顶个诸葛亮 提升方法(Boosting)基于的思想是 :对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断来得好,也就是所谓的“三个臭皮匠顶个诸葛亮”的道理。
回顾我们第一篇报告《聪明的Alpha,机器觉醒!》中用到的AdaBoost算法,它是通过组合一系列互相补充的弱分类器来构建最终的强分类器,虽然每个弱分类器的预测能力不强,但叠加效应使得强分类器的预测能力得到大幅改进。当时我们在第一篇报告《聪明的Alpha,机器觉醒》中的AdaBoost算法里构建的弱分类器可以看成只有一层但有五个节点的分类树桩,所以这里我们可以把这个弱分类器换成前面构造的决策树。以此构建的多决策树模型我们称为提升树模型。
基于Smart Alpha的选股策略 在每个月的月底,先剔除不能正常交易、涨跌停或者被特别处理的股票。为了规避行业的风险,在剩下的股票池中我们在每个中信一级行业内按照行业市值中性化的随机森林因子对股票进行降序排列,选择前10%的股票形成投资组合。以中证500为基准指数,每个行业以其在中证500中的权重加权,行业内的股票等权。
我们再次对可用于选股的机器学习算法进行了探索和革新。我们首先考察了k近邻方法,该方法的逻辑是检索历史上与目标股票因子特征最为相似的一组股票,以它们过去表现的综合水平为该股票进行打分评价。
接着,我们考察了经典的Logistic回归算法,该方法可以认为是支持向量机的姊妹方法,也是通过构造分割超平面来划分因子特征空间,每期动态调整因子权重合成为Smart Alpha因子。
最后,基于表现较好的中性化的Logistic回归因子,我们以中证500为基准构建了量化对冲选股策略,年化的超额收益率达到了 14.36%,收益风险比为 2.69,最大回撤不足 3%。另外,我们还比较了包括前面所有聪明的Alpha报告里的Smart Alpha因子的选股能力以及彼此相关性。
k近邻方法 近朱者赤,近墨者黑 K近邻方法(k-nearest neighbor,kNN)是机器学习中一种基本的分类方法,在1968年由Cover和Hart提出。对于新的输入数据,k近邻方法实际上根据其k个最近邻的训练数据实例类别,通过多数表决的方式进行预测,因此k近邻法不具有显式的学习过程。
将k近邻方法用于构建多因子模型进行选股的背后逻辑是:将因子视为股票的属性或者特征,对于某只股票,我们检索历史上与该股票因子特征最为相似的一组股票,以它们过去表现的综合水平为该股票进行打分评价。


Logistic回归 经典的回归 逻辑斯谛回归(logistic regression)是机器学习中的经典分类方法。Logistic回归主要在流行病学中应用较多,比较常用的情形是探索某疾病的危险因素,根据危险因素预测某疾病发生的概率等等。该方法由比利时数学家 P?F Verhulst 于1844年创建。

在知道因子数据的情况下,二项Logistic回归模型假设下期股票属于强势股的条件概率是Logistic分布函数的形式(上图所示),或者其对数几率是因子的线性函数。
Logistic回归类似于我们第三篇《聪明的Alpha,技术革命!》里的支持向量机方法。在特征空间中,Logistic回归也通过产生一个分割超平面来划分样本点类别。将Logistic回归或者支持向量机方法用于构建多因子模型进行选股的背后逻辑是模仿我们通常对因子加权合成综合得分而筛选股票的决策过程,从多因子模型角度看,我们也可以认为它是一个动态调整因子权重的线性多因子模型。只不过Logistic回归和支持向量机方法求解因子权重的优化目标不同而已。
基于Smart Alpha的选股策略 在每个月的月底,先剔除不能正常交易、涨跌停或者被特别处理的股票。为了规避行业的风险,在剩下的股票池中我们在每个中信一级行业内按照行业市值中性化的Logistic回归因子对股票进行降序排列,选择前10%的股票形成投资组合。以中证500为基准指数,每个行业以其在中证500中的权重加权,行业内的股票等权。
这里面我们一共探索了AdaBoost、支持向量机、决策树、随机森林、提升树、k近邻以及Logistic回归共7种机器学习算法,同时也构建了7大类Smart Alpha选股因子。
我们有了这么多的Smart Alpha因子,那到底哪个因子最后能够技压群雄,笑傲江湖呢?下面就来一个Smart Alpha因子大比拼,大伙靠实力说话,以技服人。
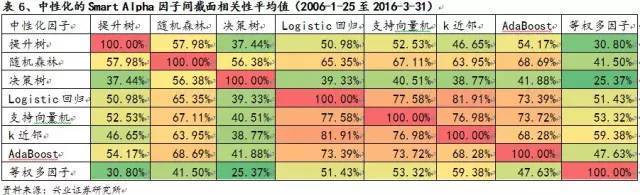
通过各番比较来看,综合实力排名靠前的算法是:AdaBoost,支持向量机以及Logistic回归。而决策树和提升树的波动性和回撤较低。Logistic回归,支持向量机,k近邻,AdaBoost算法之间的相关性相对较高。而决策树、随机森林,提升树这一类的算法同剩余的其他算法相关性相对较低。另外,所有因子总体的相关水平并不高,而且同等权多因子的相关性都相对较低。这为通过多个模型的结合来进一步分散风险提供了可能。
机器学习算法构建的Smart Alpha因子表现出了优秀的选股能力,这也使得我们坚信了机器学习或者人工智能的方法在投资领域将有更加巨大的应用潜力。另外,也希望这次关于alpha模型的一点思考能给您带来启发和帮助,同时我们也将继续探索的进程,向着更高的目标前进!


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏





