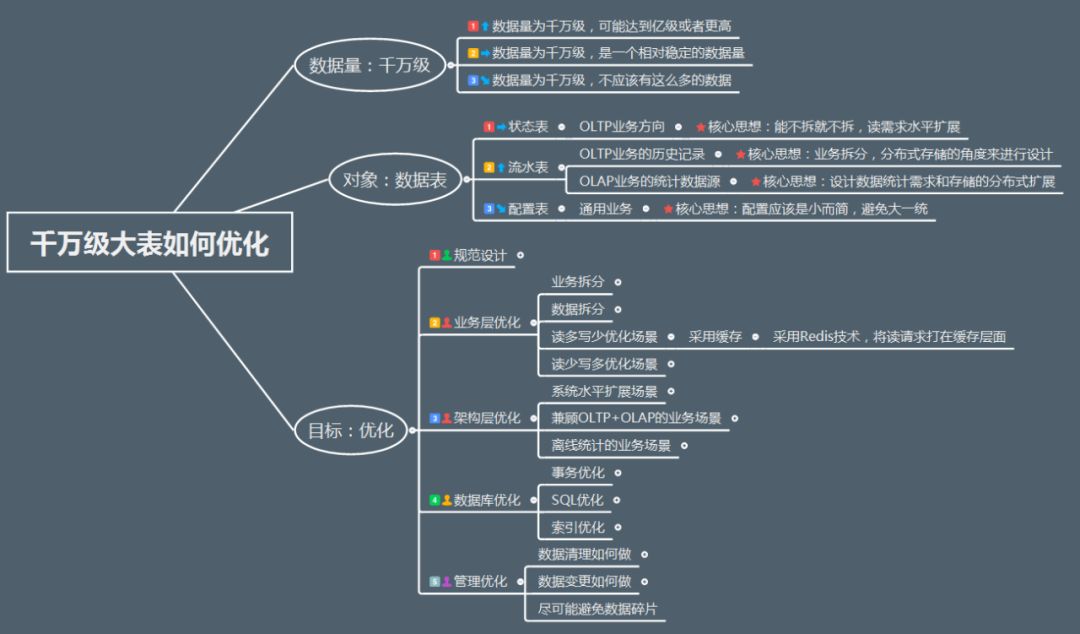
优化设计方案2:业务层优化
业务层优化应该是收益最高的优化方式了,而且对于业务层完全可见,主要有业务拆分,数据拆分和两类常见的优化场景(读多写少,读少写多)
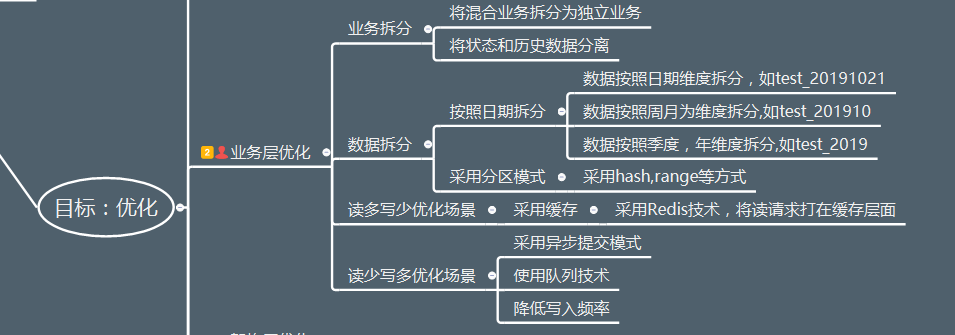
1)业务拆分
ü将混合业务拆分为独立业务
ü将状态和历史数据分离
业务拆分其实是把一个混合的业务剥离成为更加清晰的独立业务,这样业务1,业务2。。。独立的业务使得业务总量依旧很大,但是每个部分都是相对独立的,可靠性依然有保证。
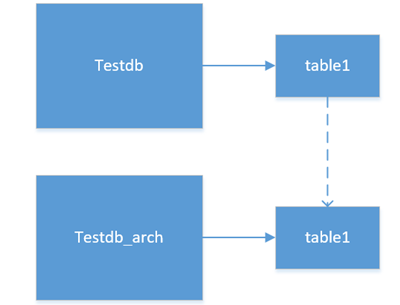
对于状态和历史数据分离,我可以举一个例子来说明。
例如:我们有一张表Account,假设用户余额为100。

我们需要在发生数据变更后,能够追溯数据变更的历史信息,如果对账户更新状态数据,增加100的余额,这样余额为200。
这个过程可能对应一条update语句,一条insert语句。
对此我们可以改造为两个不同的数据源,account和account_hist
在account_hist中就会是两条insert记录,如下:

而在account中则是一条update语句,如下:

这也是一种很基础的冷热分离,可以大大减少维护的复杂度,提高业务响应效率。
2)数据拆分
2.1 按照日期拆分,这种使用方式比较普遍,尤其是按照日期维度的拆分,其实在程序层面的改动很小,但是扩展性方面的收益很大。
数据按照日期维度拆分,如test_20191021
数据按照周月为维度拆分,如test_201910
数据按照季度,年维度拆分,如test_2019
2.2 采用分区模式,分区模式也是常见的使用方式,采用hash,range等方式会多一些,在MySQL中我是不大建议使用分区表的使用方式,因为随着存储容量的增长,数据虽然做了垂直拆分,但是归根结底,数据其实难以实现水平扩展,在MySQL中是有更好的扩展方式。
2.3 读多写少优化场景
采用缓存,采用Redis技术,将读请求打在缓存层面,这样可以大大降低MySQL层面的热点数据查询压力。
2.4 读少写多优化场景,可以采用三步走:
1)采用异步提交模式,异步对于应用层来说最直观的就是性能的提升,产生最少的同步等待。
2)使用队列技术,大量的写请求可以通过队列的方式来进行扩展,实现批量的数据写入。
3)降低写入频率,这个比较难理解,我举个例子
对于业务数据,比如积分类,相比于金额来说业务优先级略低的场景,如果数据的更新过于频繁,可以适度调整数据更新的范围(比如从原来的每分钟调整为10分钟)来减少更新的频率。
例如:更新状态数据,积分为200,如下图所示

可以改造为,如下图所示。

如果业务数据在短时间内更新过于频繁,比如1分钟更新100次,积分从100到10000,则可以根据时间频率批量提交。
例如:更新状态数据,积分为100,如下图所示。

无需生成100个事务(200条SQL语句)可以改造为2条SQL语句,如下图所示。

对于业务指标,比如更新频率细节信息,可以根据具体业务场景来讨论决定。
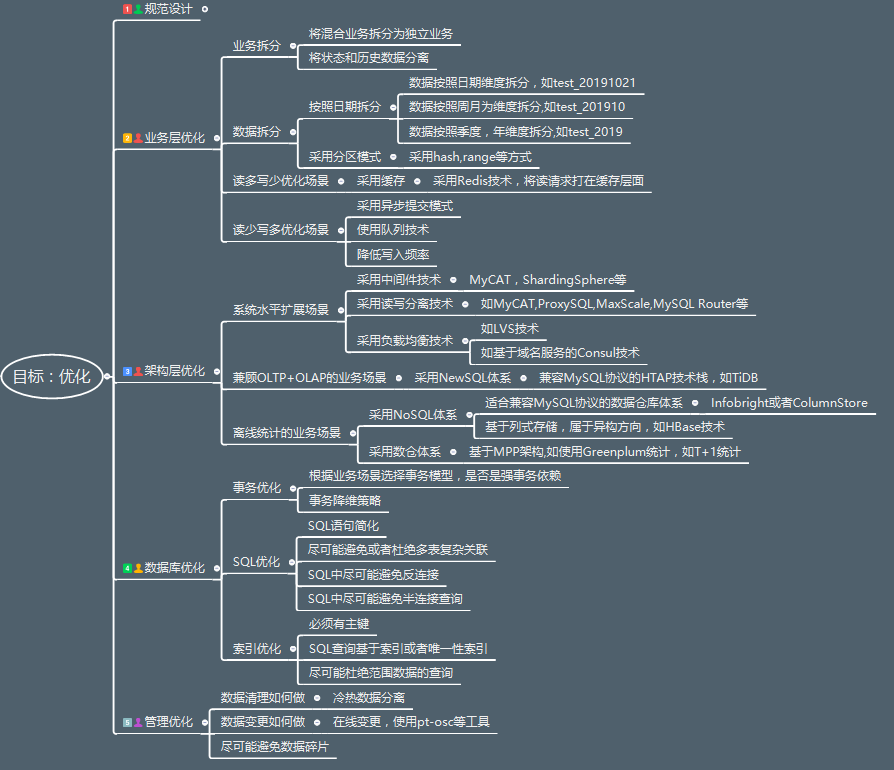
优化设计方案3:架构层优化
架构层优化其实就是我们认为的那种技术含量很高的工作,我们需要根据业务场景在架构层面引入一些新的花样来。

3.1.系统水平扩展场景
3.1.1采用中间件技术,可以实现数据路由,水平扩展,常见的中间件有MyCAT,ShardingSphere,ProxySQL等
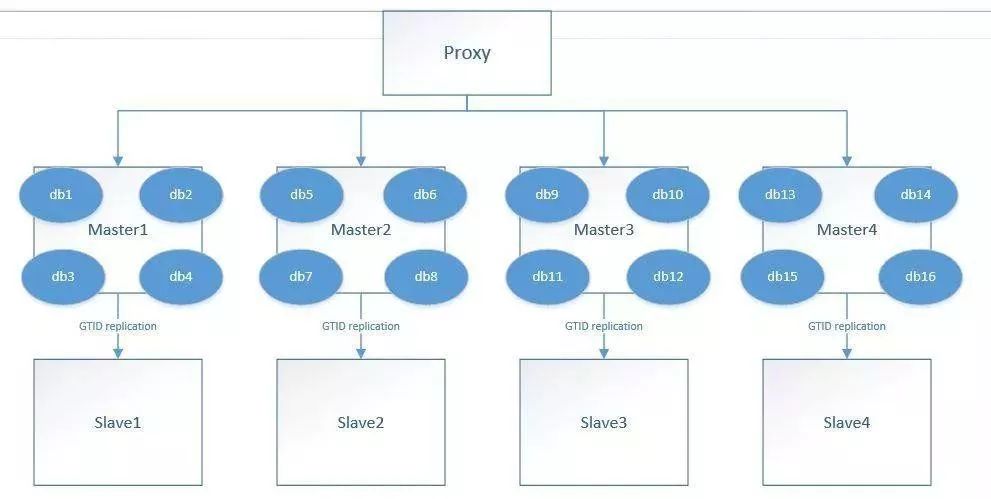
3.1.2 采用读写分离技术,这是针对读需求的扩展,更侧重于状态表,在允许一定延迟的情况下,可以采用多副本的模式实现读需求的水平扩展,也可以采用中间件来实现,如MyCAT,ProxySQL,MaxScale,MySQL Router等
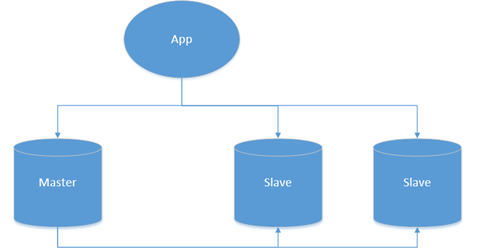
3.1.3 采用负载均衡技术,常见的有LVS技术或者基于域名服务的Consul技术等
3.2.兼顾OLTP+OLAP的业务场景,可以采用NewSQL,优先兼容MySQL协议的HTAP技术栈,如TiDB
3.3.离线统计的业务场景,有几类方案可供选择。
3.3.1 采用NoSQL体系,主要有两类,一类是适合兼容MySQL协议的数据仓库体系,常见的有Infobright或者ColumnStore,另外一类是基于列式存储,属于异构方向,如HBase技术
3.3.2采用数仓体系,基于MPP架构,如使用Greenplum统计,如T+1统计
优化设计方案4:数据库优化
数据库优化,其实可打的牌也不少,但是相对来说空间没有那么大了,我们来逐个说一下。
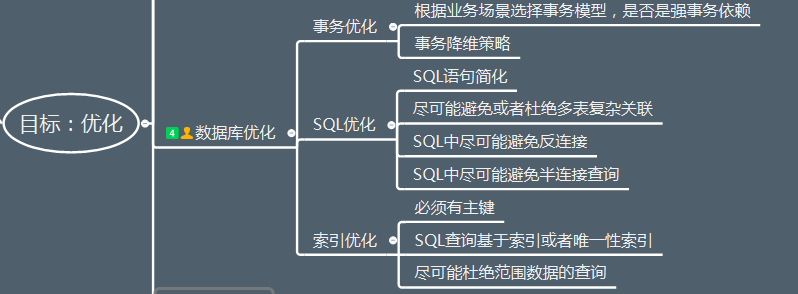
4.1 事务优化
根据业务场景选择事务模型,是否是强事务依赖
对于事务降维策略,我们来举出几个小例子来。
4.1.1 降维策略1:存储过程调用转换为透明的SQL调用
对于新业务而言,使用存储过程显然不是一个好主意,MySQL的存储过程和其他商业数据库相比,功能和性能都有待验证,而且在目前轻量化的业务处理中,存储过程的处理方式太“重”了。
有些应用架构看起来是按照分布式部署的,但在数据库层的调用方式是基于存储过程,因为存储过程封装了大量的逻辑,难以调试,而且移植性不高,这样业务逻辑和性能压力都在数据库层面了,使得数据库层很容易成为瓶颈,而且难以实现真正的分布式。
所以有一个明确的改进方向就是对于存储过程的改造,把它改造为SQL调用的方式,可以极大地提高业务的处理效率,在数据库的接口调用上足够简单而且清晰可控。
4.1.2 降维策略2:DDL操作转换为DML操作
有些业务经常会有一种紧急需求,总是需要给一个表添加字段,搞得DBA和业务同学都挺累,可以想象一个表有上百个字段,而且基本都是name1,name2……name100,这种设计本身就是有问题的,更不用考虑性能了。究其原因,是因为业务的需求动态变化,比如一个游戏装备有20个属性,可能过了一个月之后就增加到了40个属性,这样一来,所有的装备都有40个属性,不管用没用到,而且这种方式也存在诸多的冗余。
我们在设计规范里面也提到了一些设计的基本要素,在这些基础上需要补充的是,保持有限的字段,如果要实现这些功能的扩展,其实完全可以通过配置化的方式来实现,比如把一些动态添加的字段转换为一些配置信息。配置信息可以通过DML的方式进行修改和补充,对于数据入口也可以更加动态、易扩展。


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏