缺失值的识别
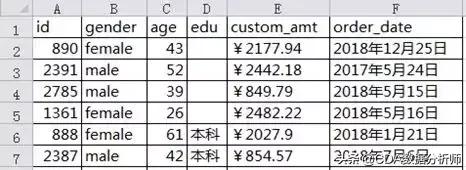
判断一个数据集是否存在缺失观测,通常从两个方面入手,一个是变量的角度,即判断每个变量中是否包含缺失值;另一个是数据行的角度,即判断每行数据中是否包含缺失值。关于缺失值的判断可以使用isnull方法。下面使用isnull方法对data3数据(数据可至中---下载)进行判断,统计输出的结果如下表所示。

如上结果所示,数据集data3中有三个变量存在缺失值,即gender、age和edu,它们的缺失数量分别为136、100和1,927,缺失比例分别为4.53%、3.33%和64.23%。
需要说明的是,判断数据是否为缺失值NaN,可以使用isnull“方法”,它会返回与原数据行列数相同的矩阵,并且矩阵的元素为bool类型的值,为了得到每一列的判断结果,仍然需要any“方法”(且设置“方法”内的axis参数为0);统计各变量的缺失值个数可以在isnull的基础上使用sum“方法”(同样需要设置axis参数为0);计算缺失比例就是在缺失数量的基础上除以总的样本量(shape方法返回数据集的行数和列数,[0]表示取出对应的数据行数)。
读者可能对代码中的“axis=0”感到困惑,它代表了什么?为什么是0?是否还可以写其他值?下面通过图表的形式来说明axis参数的用法:

假设上图为学生的考试成绩表,如果直接对成绩表中的分数进行加和操作,得到的是所有学生的分数总和(很显然没有什么意义),如果按学生分别计算总分,将是上图从左到右的转换。该转换的特征是列数发生了变化(可以是列数减少,也可以是列数增多),类似于在水平方向上受了外部的压力或拉力,这样的外力就理解为轴axis为1的效果(便于理解,可以想象为飞机在有动力的情况下,可以保持水平飞行状态)。
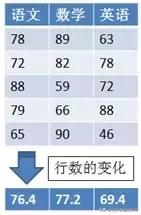
同样对于如上的学生成绩表,如果直接对成绩表中的分数计算平均值,得到的是所有学生的平均分数(很显然也没有什么意义),如果按学科分别计算平均分,将是上图中从上到下的转换。该转换的特征是行数发生了变化(可以是行数减少,也可以是行数增多),类似于在垂直方向上受了外部的挤压或拉伸,这样的外力就理解为轴axis为0的效果(便于理解,可以想象为飞机在没有动力的情况下,呈下降趋势)。
如上是关于变量方面的缺失值判断过程,还可以利用下方的代码识别数据行的缺失值分布情况:
# 判断数据行中是否存在缺失值
如上结果所示,返回True值,说明data3中的数据行存在缺失值。代码中使用了两次any“方法”,第一次用于判断每一行对应的True(即行内有缺失值)或False值(即行内没有缺失值);第二次则用于综合判断所有数据行中是否包含缺失值。同理,进一步还可以判断缺失行的具体数量和占比,代码如下:
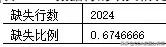
如上结果所示,3000行的数据集中有2024行存在缺失值,缺失行的比例约67.47%。不管是变量角度的缺失值判断,还是数据行角度的缺失值判断,一旦发现缺失值,都需要对其作相应的处理,否则一定程度上都会影响数据分析或挖掘的准确性。
缺失值的处理办法
通常对于缺失值的处理,最常用的方法无外乎删除法、替换法和插补法。删除法是指将缺失值所在的观测行删除(前提是缺失行的比例非常低,如5%以内),或者删除缺失值所对应的变量(前提是该变量中包含的缺失值比例非常高,如70%左右);替换法是指直接利用缺失变量的均值、中位数或众数替换该变量中的缺失值,其好处是缺失值的处理速度快,弊端是易产生有偏估计,导致缺失值替换的准确性下降;插补法则是利用有监督的机器学习方法(如回归模型、树模型、网络模型等)对缺失值作预测,其优势在于预测的准确性高,缺点是需要大量的计算,导致缺失值的处理速度大打折扣。下面将选择删除法、替换法和插补法对缺失值进行处理,代码如下:
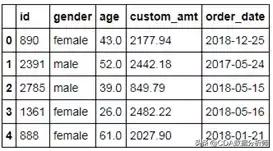
如上结果所示,表中的edu变量已被成功删除。对于字段的删除可以选择drop“方法”,其中labels参数用于指定需要删除的变量名称,如果是多个变量,则需要将这些变量名称写在一对中括号内(如['var1','var2','var3']);删除变量一定要设置axis参数为1,因为变量个数发生了变化(所以,借助于axis参数也可以删除观测行啦);inplace则表示是否原地修改,即是否直接将原表中的字段进行删除,这里设置为True,如果设置为False,则将删除变量的预览效果输出来,而非真正改变原始数据。
如上结果所示,利用drop“方法”实现了数据行的删除,但必须将axis参数设置为0,而此时的labels参数则需要指定待删除的行编号。这里的行编号是借助于index“方法”(用于返回原始数据的行编号)和isnull“方法”(用于判断数据是否为缺失状态,如果是缺失则返回True)实现的,其逻辑就是将True对应的行编号取出来,传递给labels参数。
如果变量的缺失比例非常大,或者缺失行的比例非常小时,使用删除法是一个不错的选择,反之,将会丢失大量的数据信息而得不偿失。接下来讲解如何使用替换法处理缺失值,代码如下:

如上结果所示,采用替换法后,原始数据中的变量不再含有缺失值。缺失值的填充使用的是fillna“方法”,其中value参数可以通过字典的形式对不同的变量指定不同的值。需要强调的是,如果计算某个变量的众数,一定要使用索引技术,例如代码中的[0],表示取出众数序列中的第一个(我们知道,众数是指出现频次最高的值,假设一个变量中有多个值共享最高频次,那么Python将会把这些值以序列的形式存储起来,故取出指定的众数值,必须使用索引)。
正如前文所说,虽然替换法思想简单、效率高效,但是其替换的值往往不具有很高的准确性,于是出现了插补方法。该方法需要使用机器学习算法,不妨以KNN算法为例,对Titanic数据集中的Age变量做插补法完成缺失值的处理。代码如下:


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏