CDA人工智能学院:数据科学、人工智能从业者的在线学院。
数据科学(Python/R/Julia)数据分析、机器学习、深度学习
以下使用scikit-learn中数据集进行分享。
如果精选随机森林作为最终的模型,那么发现它的最佳参数可能有1000种多种组合的可能,你可以使用使用穷尽的网格搜索(Exhaustive Grid Seaarch)方法,但时间成本将会非常高(运行很久...),或者使用随机搜索(随机搜索)方法,仅分析超参数集合中的子集合。
该示例以手写数据集为例,使用支持向量机的方法对数据进行建模,然后调用scikit-learn中validation_surve方法将模型交叉验证的结果进行可视化。需要注意的是,在使用validation_curve方法时,只能验证一个超参数与模型训练集和验证集的关系(即二维的可视化),而不能实现多参数与重叠间关系的可视化。以下搜索的参数是gamma,需要给定参数范围,用param_range进行传递,评分策略用评分参数进行传递。其代码示例如下所示:
代码中:
以下是支持向量机的验证曲线,调节的超参数gamma共有5个值,每一个点的分数是五折交叉验证(cv = 5)的均值。
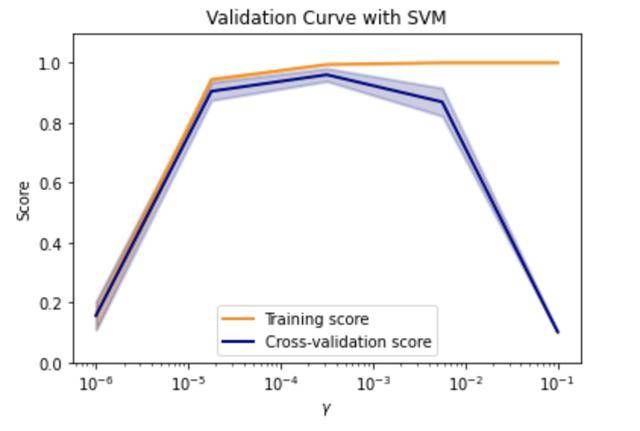
当想看模型多个超参数与模型评分之间的关系时,使用scikit-learn中验证曲线就难以实现,因此可以考虑重定向三维坐标图。
主要用plotly的库放置3D Scatter(3d 散点图)。下面的示例使用scikit-learn中的莺尾花的数据集(iris)。以下示例随机森林模型(RandomForestRegressor),利用scikit-learn中的GridSearchCV方法调试最佳超参(调整超参数),分别设置超参数“ n_estimators”,“ max_features”,“ min_samples_split”的参数范围,详见代码如下:
其运行结果如果,是一个三维散点图(3D Scatter)。
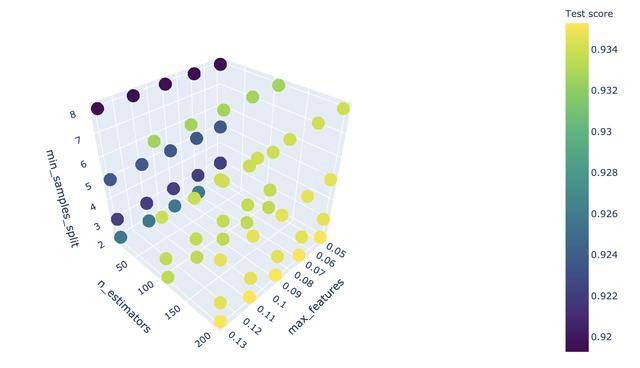
n_estimators(子估计器)越多,分数升高,max_features的变化对模型分数的影响较小,在图中看不到变化,min_samples_split的个数并非越过高越好,但与模型分数并不呈现单调关系,在min_samples_split取2时(此时,其他条件不变),模型分数最高。
除了使用scikit-learn中验证曲线以外,还可以利用seabornlib中的热图方法来实现两个超参数之间的关系图,如下示例:
max_features和min_samples与模型隐藏关系的可视化如下图所示(分别为网格搜索中测试集和训练集的重叠):
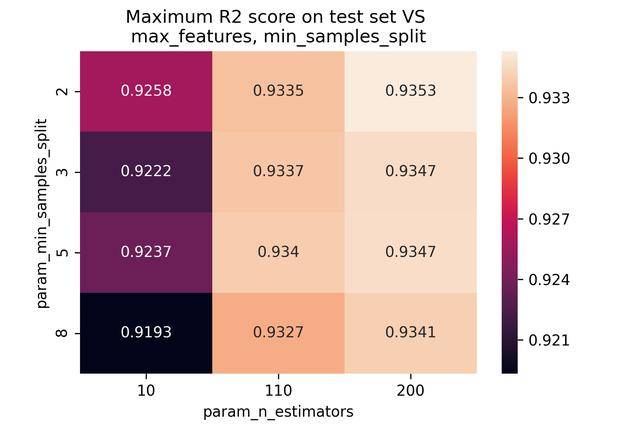
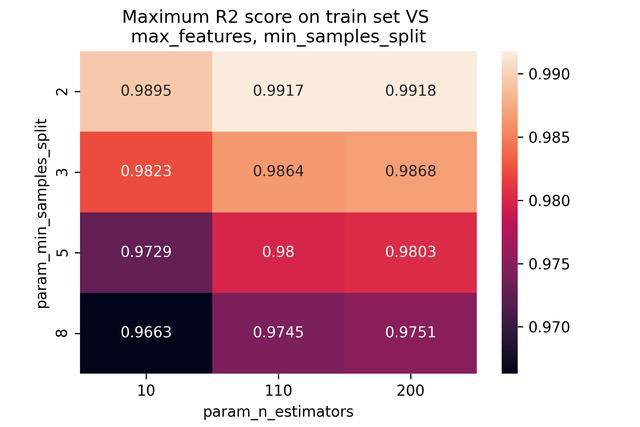
由于一般人很难迅速的在大量数据中找到隐藏的关系,因此,可以考虑绘图,将数据关系以图表的形式,清晰的显示出来。
综上,当关注局部超参数的学习曲线时,可以使用scikit-learn中验证曲线,找到拐点,作为模型的最佳参数。
当关注两个超参数的共同变化对模型分数的影响时,可以使用seaborn库中的热图方法,制作“热图”,以发现超参数协同变化对分数影响的趋势。
当关注三个参数的协同变化与模型重叠的关系时,可以使用poltly库中的iplot和go方法,转换3d 散点图(3D Scatter),将其协同变化对模型分数的影响展现在高维图中。

回复“资讯”,获取更多最新人工智能前沿动态!


 扫码加好友,拉您进群
扫码加好友,拉您进群 全部版块
全部版块 我的主页
我的主页

 收藏
收藏







